수업의 알고리즘 파트에서 정렬에 대해 배웠다.
버블 정렬, 삽입 정렬, 퀵 정렬, 선택 정렬, 그리고 병합 정렬을 배웠는데 병합 정렬이 너무 어려워서 제대로 이해하기 위해 블로그 글을 작성하게 되었다.
📌정렬의 시간 복잡도
정렬에는 기본 정렬과 고급 정렬 알고리즘이 있다.
기본 정렬 알고리즘은 버블 정렬, 선택 정렬, 삽입정렬이 있고 이들의 시간 복잡도는 O(n^2)이다.
고급 정렬 알고리즘에는 병합 정렬, 퀵 정렬, 힙 정렬, 셸 정렬이 있다. 병합 정렬과 퀵 정렬은 최악의 경우에도 O(nlogn), 퀵 정렬은 최악의 경우 O(n^2)이다. 하지만 퀵 정렬은 평균 성능이 매우 빨라서 실무에서 많이 사용된다.
📌병합 정렬
병합 정렬은 배열을 반으로 나누고 왼쪽과 오른쪽 각각 독립적으로 정렬한 뒤 정렬한 두 배열을 병합하는 정렬 방식이다.
이때 한 번만 반으로 나누는 것이 아니라 반으로 나눈 왼쪽에서도 또다시 반으로 나누고 오른쪽에서도 반으로 나누는 식으로 반복하며 원소가 1이 될 때까지 반으로 나눈 뒤 정렬하며 병합하게 된다.
크기를 2로 나눈 뒤 정렬하며 병합하는 과정을 재귀적으로 반복하게 된다.
글로는 잘 이해가 안 돼서 그림을 그려보면서 이해하려 했다.
우선 병합 정렬의 전체적인 흐름 개념 구조를 그려보면 아래와 같다.
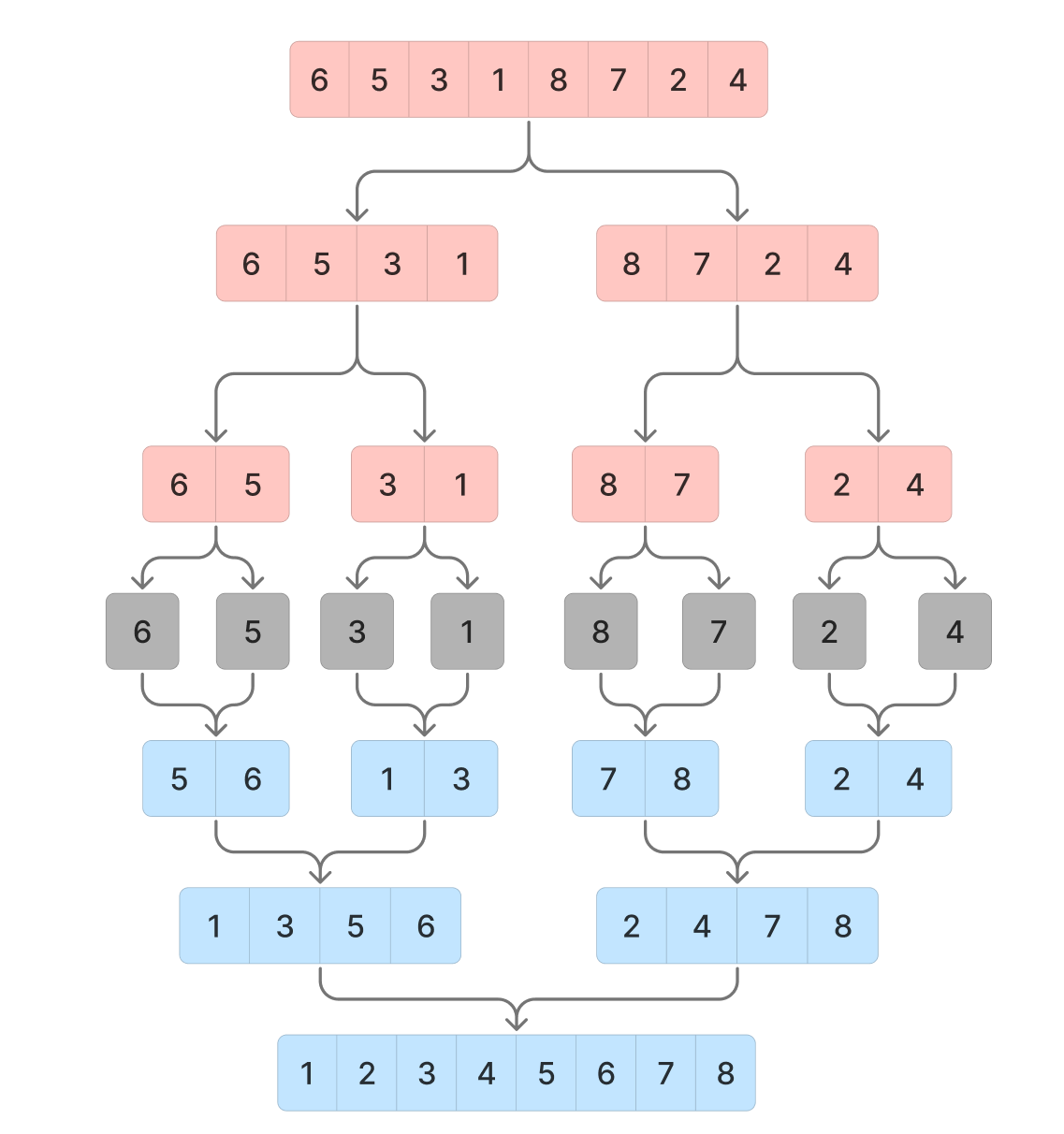
분홍색 부분은 배열 분해 과정, 파란색 부분은 배열 병합과정이다.
개념적인 부분은 그래도 비교적 어렵지 않기 때문에 위 부분까지는 바로 이해할 수 있었다.
하지만 문제는 코드 구현이었다.
재귀 부분이 평소에도 약해서인지 병합에서 재귀를 오른쪽 왼쪽 나누어서 코드로 두줄로 표현하니 너무 어려웠다.
그래서 이것도 과정을 하나하나 시각화하면서 이해하였다.
아래는 병합 정렬 의사 코드이다.
mergeSort(A[], p, r): //A[p..r]을 정렬한다.
if(p<r)
q <- ⌊(p + r) / 2⌋ //p,r의 중간 지점을 계산한다.
mergeSort(A, p, q) //전반부 정렬 ---1)
mergeSort(A, q+1, r) //후반부 정렬 ---2)
merge(A, p, q, r) //병합 ---3)
merge(A[], p, q, r):
정렬된 두 배열 A[p..q]와 A[q+1...r]을 합쳐
정렬된 하나의 배열 A[p..r]을 만든다mergeSort에서 재귀 부분이 이해하기 어려웠기 때문에 그림을 그려가면서 이해하였다.
[6, 5, 3, 1, 8, 7, 2, 4]인 배열을 병합 정렬 해보자
먼저 mergeSort의 알고리즘을 살펴본 뒤 merge 알고리즘을 살펴볼 것이다.
✔️mergeSort(A [ ], p, r)
첫 번째로 mergeSort(0,7) (배열 A는 생략) 이 호출된다.

이제 왼쪽 절반 mergeSort(0,3)을 호출하며 처리하는 과정을 살펴보자.

아래는 오른쪽 절반 mergeSort(4,7) 처리 과정이다.

양쪽이 모두 정렬되었으므로 마지막으로 merge(0,3,7)을 수행하게 된다.

✔️merge(A [ ], p, q, r)
위에서 살펴본 의사 코드에서 함수 merge()를 더 구체적으로 기술한 의사 코드이다.
//A[p..q]와 A[q+1..r]을 병합하여 A[p..r]을 정렬된 상태로 만든다
//A[p..q]와 A[q+1..r]은 이미 정렬되어 있다
merge(A[], p, q, r):
i <- p; j <- q+1; t <- 0
while(i<=q and j<=r)
if(A[i] <= A[j]) tmp[t++] <- A[i++] //의미 : tmp[t] <- A[i]; t++; i++;
else tmp[t++] <- A[j++] //의미 : tmp[t] <- A[j]; t++; j++;
while(i<=q) //왼쪽 부분 배열이 남은 경우
tmp[t++] <- A[i++]
while(j<=r) //오른쪽 부분 배열이 남은 경우
tmp[t++] <- A[j++]
i<-p; t<-0;
while(i<=r) //결과를 A[p..r]로 복사한다
A[i++] <- tmp[t++]전제 조건은 A [p.. q]와 A [q+1.. r]은 이미 정렬된 상태이고 이 둘을 합쳐서 A [p.. r] 전체를 오름차순으로 만드는 것이 목표이다.
여기서 i는 왼쪽 구간에서 현재 가리키는 원소, j는 오른쪽 구간에서 현재 가리키는 원소, t는 tmp와 A배열에 결과를 넣을 위치이다.
이 부분도 그림을 그려가면서 이해하였다.
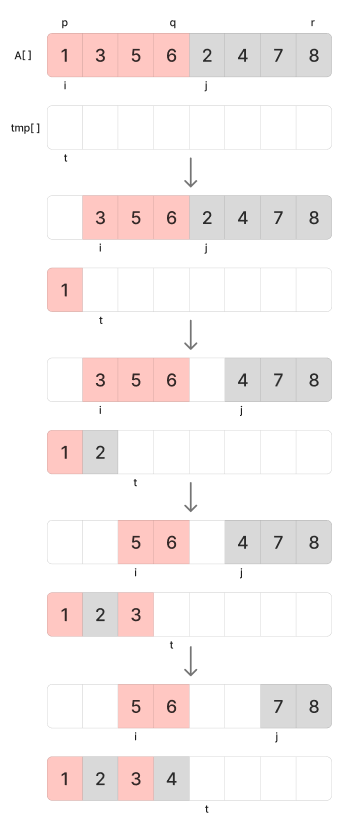

이제 코드로 구현해 보면 다음과 같다.
import java.io.IOException;
public class Main {
static int[] tmp;
public static void main(String[] args) throws IOException{
int[] arr = {6,5,3,1,8,7,2,4};
tmp = new int[arr.length];
System.out.print("정렬전:[");
for(int i=0;i<arr.length;i++) {
System.out.print(arr[i]+" ");
}
mergeSort(arr,0,arr.length-1);
System.out.print("]\n정렬후:[");
for(int i=0;i<arr.length;i++) {
System.out.print(arr[i]+" ");
}
System.out.println("]");
}
public static void mergeSort(int[] arr, int left, int right) {
if(left<right) {
int mid = (left+right)/2;
mergeSort(arr,left,mid);
mergeSort(arr,mid+1,right);
merge(arr,left,mid,right);
}
}
public static void merge(int[] arr, int left, int mid, int right) {
int i = left;
int j = mid+1;
int t = 0;
while(i<=mid&&j<=right) {
if(arr[i]<=arr[j]) {
tmp[t++]=arr[i++];
}else {
tmp[t++]=arr[j++];
}
}
while(i<=mid) {
tmp[t++]=arr[i++];
}
while(j<=right) {
tmp[t++]=arr[j++];
}
i=left;
t=0;
while(i<=right) {
arr[i++]=tmp[t++];
}
}
}
📌회고
병합 정렬을 처음 접했을 때, 재귀 함수가 두 번 연달아 반복되는 구조가 쉽게 이해되지 않았다. 머릿속으로만 그 과정을 그려보려고 하니, 흐름이 자꾸 끊기고 헷갈렸다.
그래서 직접 그림을 그려가며 분할부터 병합까지의 과정을 단계별로 정리해 봤다. 그렇게 시각적으로 구조를 확인하니, 병합 정렬이 훨씬 명확하게 이해되었다.
사실 그동안 코드 이해 속도가 다른 사람들보다 느린 것 같아 고민이 많았지만, 이번 경험을 통해 모르는 개념은 직접 그려보고 세세하게 분석하는 과정이 큰 도움이 된다는 걸 다시 한번 깨달았고 최근 나에게 큰 산이었던 병합 정렬을 드디어 이해하게 되어 뿌듯하다.
'CS > 자료구조, 알고리즘' 카테고리의 다른 글
| [Heap 힙] - JavaScript로 heap 구현하기 (0) | 2026.01.03 |
|---|---|
| 카운팅 정렬 이해하기 - Java(자바) (0) | 2025.07.06 |